


 October 1, 2024
October 1, 2024




Table of contents
As LLMs grow and become complex, their training demands increase significantly. To meet these requirements, powerful hardware is imperative. And that’s exactly why NVIDIA built Blackwell's architecture so organisations can build and run real-time generative AI on trillion-parameter large language models. In this blog, learn how NVIDIA Blackwell GPUs with their advanced capabilities and remarkable performance improvements, double LLM training workloads.
What is NVIDIA Blackwell?
NVIDIA Blackwell launched at “The #1 AI Conference for Developers” GTC 2024 is a revolutionary GPU architecture named after mathematician David Harold Blackwell. The NVIDIA Blackwell includes the powerful NVIDIA GB200 NVL/72 GPU with 208 billion transistors and HBM3e memory, which delivers up to 20 petaflops of AI performance. Blackwell GPUs are designed to accelerate the training of large AI models and generative AI applications.
NVIDIA Blackwell vs Hopper Benchmarks for LLM
NVIDIA’s official benchmarks show its superiority in LLM training tasks. These tests were conducted under MLPerf Training 4.1 standards compared to Hopper GPUs [See source]. While the NVIDIA Hopper platform has been an industry leader since its launch, Blackwell is an upgrade to NVIDIA’s powerful GPU range. When compared, Blackwell delivers double the performance per GPU on most MLPerf benchmarks, including LLM pretraining and fine-tuning as seen below.
- LLM Fine-Tuning: Up to 2.2x performance improvement per GPU for Llama 2 70B fine-tuning.
- LLM Pre-Training: Up to 2.0x performance improvement per GPU for GPT-3 175B training.
The NVIDIA Blackwell achieved double the performance for LLM workloads due to the scaling nature of the Blackwell GPUs. With larger and faster HBM3e memory, fewer Blackwell GPUs are required to run large-scale benchmarks while maintaining excellent per-GPU performance. In comparison, GPT-3 LLM Benchmark: Blackwell required only 64 GPUs while the Hopper required 256 GPUs.
Due to the rise of generative AI applications, the demand for scalable systems that support complex workloads has never been higher. Blackwell addresses this need with its focus on scalability, energy efficiency and reduced operational costs. The NVLink Switch System create a seamless infrastructure for managing multi-GPU configurations in both on-premises and cloud environments.
NVIDIA GB200 NVL72 Performance in Training and Inference
The NVIDIA GB200 NVL72 sets new benchmarks in AI training and inference, offering unprecedented performance improvements for large language models (LLMs) and high-performance computing (HPC) applications.
Click here to check the image source.
AI Training
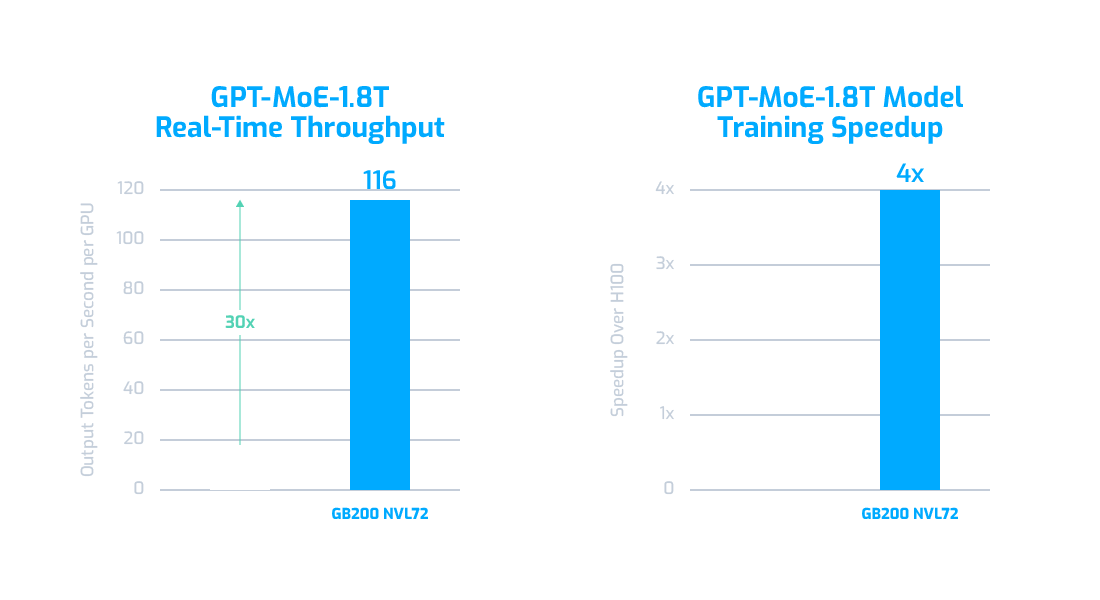
The NVIDIA GB200 NVL72 is equipped with a second-generation Transformer Engine featuring FP8 precision, which delivers up to 4 times faster training performance for large language models like GPT-MoE-1.8T compared to the same number of NVIDIA H100 GPUs. [See Source]
AI Inference
The NVIDIA GB200 NVL72 is built with cutting-edge capabilities, including a second-generation Transformer Engine that accelerates mission-critical LLM inference workloads in real-time. It delivers a 30x speedup for resource-intensive applications like the 1.8 trillion-parameter GPT-MoE compared to the previous H100 generation. [See Source]
Choosing AI Supercloud for LLM Training
Training large language models (LLMs) requires a robust, high-performance infrastructure for achieving seamless scalability and unparalleled efficiency. That's why the AI Supercloud offers more than just hardware. As an NVIDIA partner, we offer certified hardware optimised for large-scale AI workloads including:
Scalable AI Clusters
We provide configured AI clusters built using NVIDIA’s best practices. These GPU clusters for AI are tailored to meet the high computational needs of LLM training while ensuring efficiency and cost-effectiveness.
Customised for Your Workloads
For large model training, you can customise hardware and software configurations with flexible options for GPU, CPU, RAM, storage, liquid cooling, and middleware to match specific workload demands whether its fine-tuning or inference. We use the NVIDIA best practices to provide optimal performance.
Optimised Hardware for Training LLMs
Our liquid-cooled GPUs, certified storage and advanced networking solutions like the NVIDIA Quantum-X800 InfiniBand enhance performance for tasks like pre-training large models or fine-tuning advanced LLMs like Llama 3.
Workload Bursting
You can easily scale your training environment with our on-demand GPUaas platform, Hyperstack, eliminating the need for committed long-term infrastructure investments. Hyperstack offers access to powerful GPUs like the NVIDIA H100 SXM and NVIDIA A100 designed to accelerate LLM inference workloads.
Accelerate Your LLM Training with AI Supercloud
Choose AI Supercloud today to accelerate your LLM training workloads. To get started, schedule a call with our specialists to discover the best solution for your project’s budget, timeline and technologies.
FAQs
What is NVIDIA Blackwell?
NVIDIA Blackwell is a GPU architecture designed to accelerate AI workloads, featuring powerful GPUs like the NVIDIA Blackwell GB200 NVL/72 for large-scale model training.
How much faster is Blackwell than Hopper for LLMs?
Blackwell offers up to 2.2x better performance for Llama 2 70B fine-tuning and up to 2.0x better for GPT-3 pre-training compared to Hopper.
What advantages does Blackwell offer for LLM workloads?
Blackwell reduces the number of GPUs needed for LLM tasks and offers enhanced scalability, energy efficiency, and reduced operational costs.
What makes AI Supercloud ideal for LLM training
AI Supercloud provides high-performance, scalable infrastructure with AI clusters built using NVIDIA’s best practices, ensuring optimal efficiency for LLM workloads.
Can AI Supercloud help with cost management for LLM training?
Yes, AI Supercloud allows workload bursting and flexible on-demand GPU usage through Hyperstack, enabling cost-effective scaling without long-term infrastructure commitments.
Share this post



