


 October 1, 2024
October 1, 2024




Table of contents

In our blog, we will discuss the groundbreaking features of the NVIDIA Blackwell GPU architecture, including its massive computational power, enhanced Transformer Engine, secure AI capabilities and impressive NVIDIA Blackwell GPU specs for the GB200 NVL72 system.
The NVIDIA GTC 2024 was indeed revolutionary because it marked the much-anticipated launch of NVIDIA Blackwell. Since the release of NVIDIA’s latest architecture, everyone across the AI space is excited to use its innovative capabilities for large-scale AI model training and inference. But how does the NVIDIA Blackwell achieve top-tier performance? Let’s explore in our latest article below!
What is NVIDIA Blackwell Architecture?
The NVIDIA Blackwell architecture was officially launched on March 18, 2024, during the GTC 2024 keynote in San Jose, California. As a next-generation Blackwell NVIDIA architecture, it marks a new era in generative AI compute. The Blackwell architecture is named in honour of the renowned American mathematician and statistician David H. Blackwell. The NVIDIA Blackwell architecture extends far beyond the previous GPU technologies with features designed to meet the complex demands of generative AI models. The Blackwell architecture offers state-of-the-art performance, perfect for supporting multi-trillion parameter models with real-time efficiency.
What are NVIDIA Blackwell Features?
The NVIDIA Blackwell GPU is engineered for performance and scalability. Below are some of the key features of the Blackwell GPU that make it a game-changer in the world of AI and HPC.
A New Class of AI Superchip
The Blackwell GPU is the largest NVIDIA Blackwell GPU ever created, featuring 208 billion transistors—more than 2.5 times the transistors in NVIDIA's Hopper GPUs. It utilises TSMC’s 4NP process, specifically developed for NVIDIA. Blackwell offers groundbreaking compute performance, reaching 20 petaFLOPS on a single chip. It achieves this by combining two large dies into a unified GPU, with each die being as large as possible within reticle size limits. These dies are linked via a high-speed 10 terabit-per-second (TB/s) NV-HBI interface, enabling full coherence and a seamless GPU experience.
Second-Generation Transformer Engine
The second-generation Transformer Engine powers up large language models (LLMs) and Mixture-of-Experts (MoE) models, using Blackwell Tensor Core technology. To improve MoE models, Blackwell Tensor Cores introduce new precision options and scaling techniques to boost accuracy and throughput.
Optimised for performance, these changes double the performance of FP4 Tensor Cores and increase memory bandwidth. The enhancements make real-time MoE model inference more accessible with lower hardware and energy demands. For training, expert parallelism techniques paired with NVLink provide outstanding performance, enabling efficient handling of models with over 10 trillion parameters.
Confidential Computing and Secure AI
NVIDIA Blackwell introduces Confidential Computing to protect sensitive data, extending Trusted Execution Environments (TEE) to GPUs. As the first TEE-I/O-capable GPU, Blackwell offers robust, secure, and high-performing solutions for handling LLMs and confidential AI training. It ensures excellent throughput in encrypted modes and safeguards AI intellectual property. These capabilities allow secure AI training, inference, and federated learning, protecting sensitive models while maintaining performance.
Fifth-Generation NVLink and NVLink Switch
The new NVLink in the NVIDIA Blackwell architecture boosts data transfer across up to 576 GPUs, facilitating the acceleration of large AI models with trillions of parameters. Fifth-generation NVLink improves on its predecessor by doubling bandwidth to 50 GB/sec per link in both directions. Blackwell GPUs use 18 NVLink connections to provide 1.8 TB/sec of total bandwidth, significantly outpacing PCIe Gen5. The NVLink Switch supports model parallelism across multiple servers, offering up to 130TB/s GPU bandwidth, ensuring the seamless scaling of large models.
Decompression Engine
The new Decompression Engine in Blackwell accelerates data processing at up to 800GB/s. When combined with the 8TB/s HBM3e and the high-speed interconnect of the Grace CPU, this innovation speeds up data queries, making Blackwell 18X faster than CPUs and 6X faster than NVIDIA H100 GPUs in database operations. This enables fast, efficient data analytics and science processing.
RAS Engine
Blackwell's architecture includes a dedicated RAS Engine, ensuring intelligent resiliency by monitoring hardware and software health. Using AI-driven predictive management, it detects potential faults and prevents downtime. This proactive monitoring improves system stability, optimising energy usage, and minimising computing costs, ensuring uninterrupted operation.
NVIDIA Blackwell Specs: NVIDIA GB200 NVL72
The NVIDIA Blackwell GB200 NVL72 cluster represents the most powerful configuration built on the NVIDIA Blackwell GPU architecture. This system showcases the full potential of NVIDIA Blackwell GPU specs, integrating 36 GB200 Superchips. Each Superchip consists of 36 Grace CPUs and 72 Blackwell GPUs, creating a high-performance GPU-to-GPU interconnect structure known as the NVLink domain. This cluster design combines cutting-edge hardware to provide an unmatched computing platform capable of acting as a single large GPU. With this innovative setup, the GB200 NVL72 delivers performance improvements of up to 30 times faster real-time trillion-parameter large language model (LLM) inference compared to previous generations. These advanced Blackwell GPUs offer unmatched performance for training and inference.
Use Cases of NVIDIA GB200 NVL72
The NVIDIA Blackwell GB200 NVL72 is designed to handle complex workloads such as:
Real-Time Inference
The NVIDIA GB200 NVL72 is equipped with a second-generation Transformer Engine, which accelerates LLM inference tasks, including the demanding multi-trillion parameter models, enabling real-time results. It offers a 30X speed increase over the previous-generation H100 in large models like GPT-MoE 1.8T (see below) using advanced Tensor Core technologies that support the new FP4 precision for faster and more efficient inference. NVLink and the powerful liquid-cooled 72-GPU rack provide a unified computing environment capable of tackling large AI workloads with no bottlenecks.
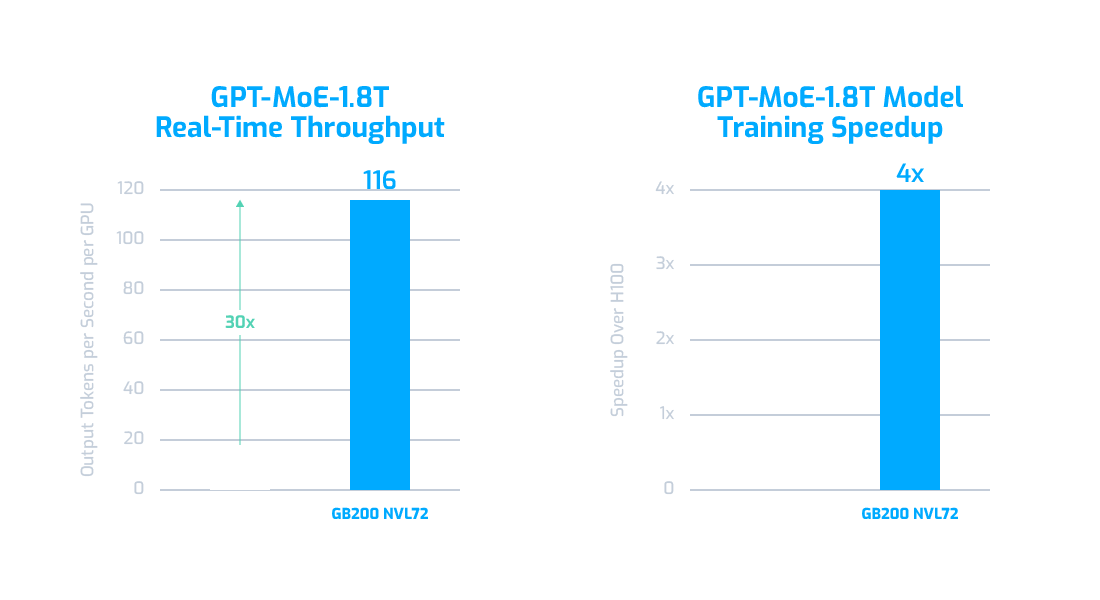
Source: NVIDIA GB200 NVL72 LLM Training and Real-Time Inference
AI Training
The NVIDIA GB200 NVL72 accelerates AI model training performance, particularly for large-scale LLMs such as GPT-MoE-1.8T, by providing 4X faster training speeds compared to the Hopper GPUs. This improvement leads to a 9X reduction in required rack space, offering significant savings on total cost of ownership (TCO) and energy usage. Its combination of fifth-generation NVLink interconnects with 1.8 TB/s GPU-to-GPU bandwidth, and InfiniBand networking enhances scalability for growing enterprise needs.
Data Processing
The NVIDIA GB200 NVL72 cluster enables accelerated data processing, offering up to 18X faster database query performance than traditional CPUs. Using NVLink-C2C and Blackwell’s Decompression Engine, the NVIDIA GB200 dramatically improves data analytics and data science workflow. This makes it an ideal choice for enterprises looking to efficiently process large volumes of data.
NVIDIA Blackwell GB200 NVL72/36 on the AI Supercloud
On the AI Supercloud, we don’t just provide the hardware- we optimise it to meet your specific project needs with NVIDIA best practices. We provide customisation at server and solution levels, including additional inference cards and separate shared storage options designed to meet your needs. The NVIDIA GB200 NVL72/36 on the AI Supercloud is equipped with liquid-cooled technology, fifth-generation NVLink, NVIDIA Quantum-X800 InfiniBand, NVIDIA-certified WEKA storage with GPUDirect Storage support and cutting-edge CPU-GPU connectivity to create the ideal environment for training and inference.
Whether you're building a generative AI product or scaling enterprise infrastructure, the Blackwell NVIDIA architecture provides the scalability and security your AI stack needs. Schedule a call with our solutions engineer to discuss how we can customise an AI solution that best suits your needs. Let us help you optimise NVIDIA GB200 NVL72/36 for your high-performance AI needs.
Similar Reads:
FAQs
What is NVIDIA Blackwell?
NVIDIA Blackwell is the latest GPU architecture designed for generative AI, featuring groundbreaking compute performance and optimised for large-scale AI models. The NVIDIA Blackwell GPU series includes powerful systems like the GB200 NVL72, designed to handle trillion-parameter LLMs with ease.
What are the key features of NVIDIA Blackwell?
Blackwell includes a second-generation Transformer Engine, 208 billion transistors, confidential computing for secure AI, and advanced NVLink for high-speed GPU connectivity.
What is the NVIDIA Blackwell GPU Architecture?
The NVIDIA Blackwell GPU architecture is a cutting-edge platform developed to power the next generation of AI, offering exceptional performance for large-scale training and inference.
Does the NVIDIA Blackwell use NVlink?
Yes, the NVIDIA Blackwell uses fifth-generation NVLink with 50GB/sec per link bandwidth and supports up to 576 GPUs, providing seamless scaling for large AI workloads.
How does Blackwell ensure data security for AI applications?
Blackwell introduces Confidential Computing and Trusted Execution Environments (TEE) to securely process sensitive data, safeguarding AI intellectual property during training and inference.
When are NVIDIA Blackwell GPUs Coming Out?
NVIDIA Blackwell GPUs such as the NVIDIA GB200 NVL72/36, are expected to be available by the end of 2025. Early access reservations are available through AI Supercloud for those wanting to leverage its cutting-edge capabilities in generative AI and HPC.
Share this post



